
Developers: Human-to-Human communication with flexible audio technology
In our series on Audio Technologies, DSP Concepts contributed a blog on Building Voice Assistants for Home Audio, followed by both Fundamentals of Voice UI: Part I: Building Blocks and Fundamentals of Voice UI: Part II: Designing Optimum Beamformers.

Examples of personal communications
Audio technologies are important for Qualcomm Technologies' audio products for the delivery of crisp, clear listening experiences for a wide range of products. We are pleased to have DSP Concepts, a leading provider of Audio development tools, as part of our ecosystem community.
For this next guest blog, DSP Concepts' team explains how human-to-human communication differs from human-to-machine and how to meet the challenges of noise suppression when choosing the audio front end — the digital signal processing required to clean the microphone signal for the best possible transmission.
Human to machine, human to human
Voice assistant devices are different from Voice communication devices in a number of ways requiring special attention to developing an audio front end.
Voice assistants are essentially machine listeners that facilitate human-to-machine communication by understanding voice commands and responding with synthetic voice, audio cues, or visual feedback. Machines must capture the intent of the command to respond accurately to the user. While ambient noise suppression is necessary to clean up the incoming audio before passing it on to the local or cloud command processing engine, the processing required to deliver intelligible wake words and commands for voice calls can be less selective than the processing required for intelligible speech transmission to a human listener.
On the other hand, voice communication devices support human-to-human communication with the expectation that human listeners on each end need to hear intelligible, clear voices without artifacts or interfering background noise. Listener fatigue is a point of concern for human listeners, wherein the user may experience discomfort and an oversensitivity or loss of sensitivity toward particular sounds or ranges of frequencies. While machine listening does not require eliminating speech artifacts such as distortion and echo, these artifacts significantly add to listener fatigue on a voice call. Therefore, the audio front ends designed for voice communication must deliver intelligible speech that minimizes many kinds of interference while also sounding natural.
A comparison of the human-machine and human-human communications is shown in Table 1 below.
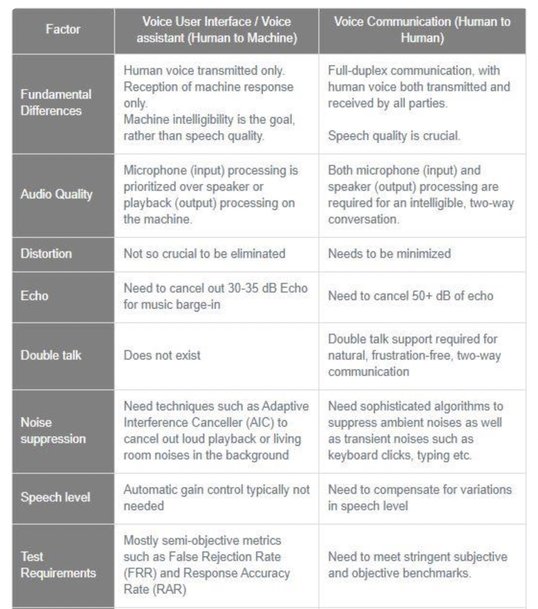

Human-machine and human-human communications comparison
Voice communication use cases
Recent trends in virtual communication have seen a rise in use cases for voice communication that increase personal and work productivity and facilitate remote communication with family and friends. Use cases can be categorized based on the typical distance between the user and the device:
- Close-talk: The user's mouth and the device microphone are in close proximity, e.g., hearables and headsets.
- Near-field: The user is less than 1 meter from the device, e.g., a microphone array built into a notebook computer or a visitor speaking into a front-door security camera or intercom.
- Mid-field: The user is within 3 meters of the device, e.g., seated in a conference room addressing a TV-mounted camera.
- Far-field: The user is 5 meters or farther away from the device, e.g., a user at the corner of the room talking to a wall-mounted huddle room conferencing system.
The following show the range of voice communication use cases:
Personal communications
As seen in Image 1, personal communication devices allow wideband voice calls in close-talk and hands-free scenarios. Indoor devices must cancel out typical stationary and non-stationary noise to be most effective. In contrast, outdoor devices have the additional requirement of suppressing interference such as wind and traffic noise.
Here are some examples of personal communication devices:
- Wearables and Hearables: Categorized as close-talk devices, headsets and hearables used for full-duplex voice calls in both indoor and outdoor environments must be capable of suppressing various noise profiles. 2-microphone arrays with fixed beamformers are recommended and acoustic echo cancellation provides clear voice calls when using these devices. One microphone is sufficient for wrist-worn hearables.
- Smart Home and Home Security: smart displays and security panels offer video calling and feature user tracking using a camera's pan and zoom functions or even motorized bases (e.g., as found on the Amazon Echo Show 10). As the user speaks from various positions and distances, the integrated microphone arrays should reliably operate in the near- and mid-field range and feature either fixed or adaptive beamformers.
- Smart TV and Sound Bar: a Smart TV can be a hub to monitor security cameras and utilize video calling devices. Products such as Facebook Portal can interface with various videoconferencing services and can be used at distances farther than would be feasible using a smartphone or tablet. This use case requires integrated microphone arrays to support mid- to far-field range voice communication in living rooms and home offices.
- Health & Fitness: smart fitness equipment used at home, such as Peloton Bikes, allow flexibility to call friends or participate in group training sessions. These next-generation health and fitness devices require robust audio front ends for near to mid-field operation with acoustic echo cancellation and noise suppression to allow the user to move away from the equipment as needed.
Workplace communications
Workplace and home office collaboration has increased the need for clear voice communication. Remote conferencing has risen exponentially with the growth of home office devices such as USB speakerphones and others, as seen in Image 2. It is expected to evolve to address new use cases for hybrid workplace environments.
Speech quality is of the highest priority in workplace communications. Therefore, major players such as Zoom and Microsoft have created certification requirements for device vendors. More details on the certification requirements will be covered below.

Examples of personal communications in the workplace
Here are some examples of workplace devices:
- Home Office: conferencing devices include speakerphone products connected to a laptop via USB, Bluetooth or Wi-Fi connectivity, notebook computers with built-in microphone arrays, USB webcams with integrated microphones; all are operating in a near-field environment. Close-talk devices such as headsets are also common. A crucial requirement for these devices is natural voice quality in full-duplex conversations with no keyboard clicking noises.
- Huddle Rooms: Videoconferencing in small rooms with 2-3 people using VoIP desk phone or tabletop or wall-mounted conference speaker, sometimes connected to a smart TV display, need clear and natural voice calls. These calls must have good double-talk performance so that everyone can be heard equally well in conference calls.
- Board Rooms: In mid- to large-sized conference rooms with wall-mounted conference systems or centrally positioned tabletop conference speakers, the audio system can be integrated into the main unit or extended from the main unit with additional microphones distributed evenly across the table or around the room. Other form factors of these systems may include video bars, flush-mount or hanging microphones installed in the ceiling, and boundary microphones positioned elsewhere.
- These high-end conferencing systems need to deliver full-duplex calls with the highest voice clarity, along with additional features such as adaptive beamforming and loudspeaker processing. In addition, they should be able to reliably operate in the far-field when users are located in any corner of the room.
Gaming communications
Gaming voice chat with wired or wireless headsets offers flexibility for multiplayer gaming communication, but listener fatigue is a primary concern. Possible solutions to listener fatigue include soundbars or speaker-equipped computer monitors with integrated microphone arrays and processing, as shown in Image 3. These products offer full-duplex communication in the near to mid-field without the need for headsets or headphones to provide even more gaming flexibility. With effective acoustic echo cancellation, such products could provide clear voice chat between users even with sound effects and music playing on each end of the connection.

Examples of gaming communications
Public communications
Apart from personal and workplace communication use cases, public-facing applications such as retail kiosks and medical devices can also benefit from enhancements in voice communication technologies.

Examples of public communications
Here are some examples of public communications devices:
- Kiosks: Retail and customer service kiosks are typically specified for the near-field range but can have many requirements based on location. Indoor kiosks require the cancellation of typical indoor ambience such as fan noise or interfering speakers, while outdoor kiosks also require cancellation of wind noise.
- Medical Devices: Telehealth is a growing trend, with voice communication at its core for inpatient care or after-visit communications. From near-field wearable devices used for hospital communications to nursing call stations used for video appointments with patients, full-duplex, high-quality voice calling is the key to effective communication between health care providers and their patients.
Voice communication processing
Designing a voice communication product starts with carefully selecting hardware and software components to achieve the desired audio quality within cost constraints, form factor, and use-case.
A successful product design should effectively mitigate acoustic echo, speaker distortion, and ambient noises to provide natural, clear, and full-duplex voice quality. To avoid using multiple software solutions to cover each desired feature, processing for voice communication should also co-exist with voice assistant and playback processing in most devices.
There are many different algorithms at work in Voice Communication products that help achieve a distortion-free full-duplex experience, including DSP Concept’s TalkTogether. TalkTogether provides processing for natural, full-duplex, person-to-person voice communication, with the Audio Weaver system (a low-code, processor-independent development platform) that removes the complexity and risk when designing and deploying voice communication processing to personal, workplace, gaming, and public communications devices.

Audio Weaver and TalkTogether from DSP Concepts
You can learn more about TalkTogether and Audio Weaver, along with their components, in our blog post, Building Voice Assistants for Home Audio.
Three additional building blocks not mentioned in that blog post but very important to audio front ends are:
1. Full duplex communication provides clear voice quality even when speakers on both sides are talking simultaneously. Without this, you must wait until the other party stops talking in order for you to get a word in.
When the far-end signal (from the remote caller) causes an acoustic echo while a near-end signal is present (the local user's voice), the adaptive filters responsible for AEC cannot accurately predict the echo path. This disruption results in more than just the intended echo being canceled, the intelligibility of the conversation can be compromised. System delays and ambient noise conditions can exacerbate double talk, further impacting the quality of communication.
AEC with double talk detection is commonly used in conferencing solutions present in office environments. However, applications such as smart fitness equipment need advanced methods of echo cancellation to eliminate double talk from group conference calls while background music playback is present, as is often the case in public areas.
2. Noise Suppression preserves the speech quality in voice calls by eliminating stationary ambient noises such as HVAC or fan noises, transient noises such as keyboard clicks, and non-stationary background noises such as loud interfering music. Single-microphone solutions include Single Channel Noise Reduction (SCNR) that suppresses stationary noises up to 10 dB. In contrast, multi-microphone solutions include Beamformers, SCNR, and other machine learning based noise processing to eliminate hard-to-remove, non-stationary and transient noises to deliver a noise-free signal.
Multiple noise suppression modules are available in TalkTogether, including:
- De-Reverb removes reverberation effects in tightly enclosed spaces such as offices or living rooms with reflective walls. TalkTogether De-Reverb extends the echo canceller performance in huddle room conferencing and gaming scenarios to provide reliable speech quality.
- Wind Noise Suppression delivers clear speech in extreme wind noise conditions extending voice communication capabilities to outdoor applications such as security cameras, video doorbells, and hearables/wearables.
- Keyclick Removal eliminates annoying keyboard and mouse clicks from the participants in a conference call.
- Automatic Gain Control (AGC) for outgoing and incoming signals allows for rapid changes in level to be dynamically adjusted for a more consistent speech level. AGC is especially useful in conferencing applications where the participants are at varying distances from the device.
- Aggressively tuned noise suppression and AGC can reduce speech quality resulting in a muting effect. Therefore, this processing must be carefully tuned with loudness and distortion requirements in mind. Furthermore, conferencing services (e.g., Google Meet) might also apply noise suppression. This cascading signal processing can result in an additional stage of noise reduction to the already clean signal, ultimately degrading speech quality.
3. Loudspeaker Processing includes Equalizer (EQ), Dynamic Range Compression (DRC), and AGC to dynamically equalize the remote caller's signal and deliver a clear, distortion-free speech to the local user. TalkTogether loudspeaker processing can be further extended to enhance speech quality as needed for the application with the 500+ audio processing modules available in Audio Weaver.
Integrating the above voice communication processing into an end product requires careful selection and tuning of hardware and software components to mitigate implementation risks and time-to-market. Seamless integration of voice communication, voice UI, and Playback features requires developers to make smart choices, from selecting the audio development system to defining the tuning and debugging strategy to meet industry standard requirements. The section below describes the workflow to design a robust voice communication product with reduced risk and complexity to speed time to commercialization.
Design workflow
When designing your audio front end, there are a number of considerations. For more detail, check back on our blog, Building Voice Assistants for Home Audio. But let’s take a quick look at a few of those considerations more relevant to our use cases mentioned above:
Component Selection: The design specification of any voice product is defined by its form factor. From tiny TWS headsets to large huddle room conferencing soundbars and public communication kiosks, the design choices for processors, microphones, loudspeaker components and software algorithms determine the resulting audio quality. Components may include:
Microphone array selection - Choice of microphone array geometry and microphones depend on product form factor and performance requirements. A single or dual-microphone linear array should suffice for a consumer conferencing product to process the incoming speech from a user sitting directly in front of the device. Likewise, users of a wall-mounted device may be situated in mid to far-field range, so a linear microphone array for that product can provide the required 180-degree field of operation.
Table-top speakerphones are generally intended for a 360° field of operation. However, the microphone array geometry can be varied depending on whether the product is specified for both near- and far-field ranges. In these products, the number of microphones and selected array geometry depends on the intended distance. A 2-microphone array may suffice for the near-field range, while a 4-microphone trillium or circular array with DoA and adaptive beamforming is necessary for the desired level of performance with sources in the mid- to far-field range.
Processor Selection - The design performance depends on the choice of algorithms, which can be tailored to fit the constraints of available CPU clock speed and memory on the selected platform. A voice communication design using one or two microphones with fundamental building blocks such as fixed beamformers and echo cancellation can be run on a Micro-controller Unit (MCU). Designs that integrate advanced AEC algorithms or support voice activation together with TalkTogether need to be run on a System on Chip (SoC) or a Digital Signal Processor (DSP). For OEMs building products with multiple form factors, a processor-agnostic audio development platform avoids delays and allows rapid iteration and evaluation.
Additionally, product design benefits from using an SoC with integrated audio DSP and a high audio interface channel count. The Qualcomm QCS400 series smart audio SoCs feature a high-performance, low-power architecture with dual DSPs, Wi-Fi and Bluetooth connectivity, powerful audio features with support for up to 32 channels, and the Qualcomm® AI Engine on a single chip.
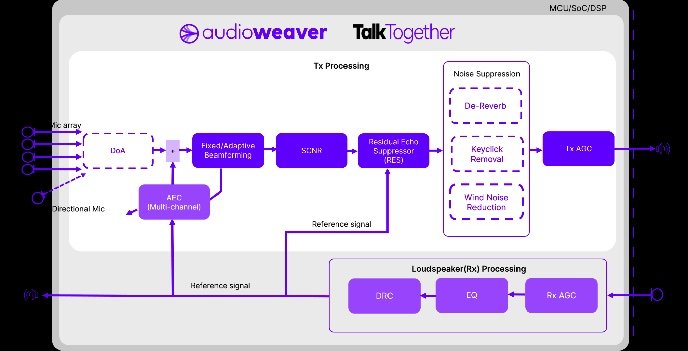
TalkTogether block diagram
Rapid Prototyping: Designing any audio product is a challenging task with long design cycles and multiple iterations of prototyping, Design Verification Test (DVT), Engineering Verification Test (EVT), and Production Verification Test (PVT) stages. However, with a flexible platform such as Audio Weaver, risks can be mitigated early in the prototyping stage. Rapid prototyping, wherein designs can be quickly developed, tested, and iterated, is the key to building voice communication products against the required design specification or form factor.
One of the significant difficulties of designing small form-factor conference phones is mitigating the distortion from small speakers used in the design. Rigorous prototyping in the early stages helps optimize the distortion metrics, reducing the risks involved with changing the design components later. Similarly, the location of microphone and speakerphone components on the product, microphone geometry, etc., should be identified at the prototyping phase to reduce potential roadblocks.
Device Certification: Device OEMs must meet several industry certifications to highlight their products as having met Alexa Calling, Messaging and Announcements (ACM) and Microsoft Teams certification. An audio development environment should allow designers to easily debug and tune their designs to meet multiple certifications.
Audio Weaver's real-time graphical interface helps developers create audio products with minimal cost and development time to meet several industry standard certifications such as ACM and Microsoft Team certifications. In addition, Audio Weaver provides a platform with all the key design aspects to scale from single microphones to multi-microphone architectures. Audio Weaver allows developers to rapidly prototype and validate hardware designs for microphone array selection, component placement and algorithm definition.
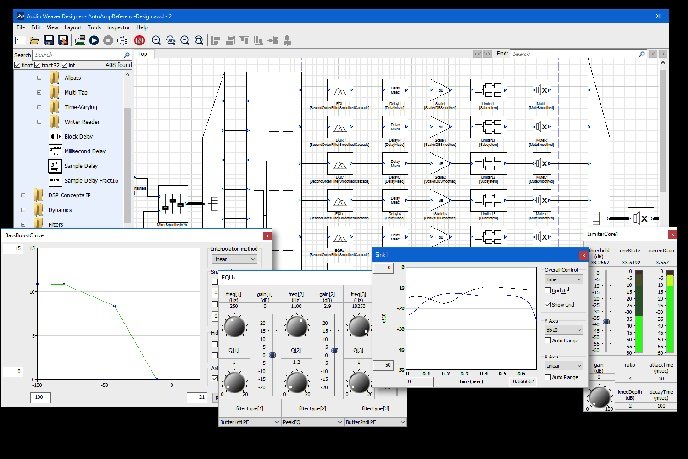
Audio Weaver designer
Debugging and Tuning: Audio system tuning is a significant investment for development teams in terms of cost and time. Voice communication designs must meet acoustic performance metrics and optimize CPU and memory usage designs on the target hardware platform. Audio systems integrate several hardware components such as SoC/DSP, microphone, loudspeakers, etc., making it challenging to debug issues at the final form factor stage.
Audio system developers should also consider flexible tools and methodologies to design, test, tune, and deploy audio products to avoid production delays. The audio development environment should have built-in debugging capabilities to verify functional and system issues on the hardware target. This includes troubleshooting mechanical design challenges such as microphone isolation, sensitivity matching between microphones, CPU clock synchronization, audio latency issues etc., that can increase the risk of production delays with each stage in the product development cycle.
Reference designs
Are you ready to build your voice communication product? Reference designs are a great first step to build voice communication products with a short product cycle. Reference designs help to develop a proof of concept on the target hardware to evaluate the acoustic performance before integrating it into the final product. DSP Concepts has several TalkTogether reference designs on high-performance platforms such as the Qualcomm QCS405 system on a chip (SoC). For an example of such reference designs please review our Qualcomm Smart Audio 400 Platform product brief. DSP Concepts technology runs either on the ARM Cortex-A53 processor, or equally well on the Qualcomm® Hexagon DSP. Utilizing the Hexagon DSP for Audio Weaver designs can free up the A53 processor for other tasks.
Conclusion
Voice calls have existed for decades, albeit with slow progression in technological advancements. The recent, dramatic increase in use cases creates a favorable trend for innovative applications for voice communication spanning across personal, workplace, gaming and public communication sectors. In addition, increasing consumer expectations for audio quality of communication devices calls out for premium products that deliver consistent user experience and superior audio quality. Therefore, we can expect to see evolution in available voice communication products as we move towards a hybrid environment.
www.qualcomm.com
